Generative Cooperative Learning for Unsupervised Video Anomaly Detection review
Generative Cooperative Learning for Unsupervised Video Anomaly Detection 리뷰
##Generative Cooperative Learning for Unsupervised Video Anomaly Detection 리뷰
this paper accepted Computer Vision and Pattern Recognition Conference (CVPR) 2022
##Abstract Video의 Anomaly Detection은 weakly-supervised와 one-class classification (OCC)에서 잘 관찰된다. 그러나 Unsupervised Anomaly Detection은 매우 드물다 -> anomalies는 자주 발생하지 않고 일반적으로 정의되지 않기 때문이다. = ground truth supervision과 결합될 때 학습 알고리즘의 성능에 부정적인 영향을 미칠 수 있다.
이 문제를 해결하기 위해 저자들은 Unsupervised Generative Cooperative Learning (GCL) 접근 방식을 제안한다. -> Generator와 Discriminator 사이의 cross-supervision을 구축하기 위해 anomalies의 low frequency를 이용하는 방식이다.
[Introduction] In the real world에서 Learning-based Anomaly Detection은 사건의 드문 발생률 때문에 매우 어렵다. 이러한 도전들은 사건들의 제역없는 특성으로 인해 더욱 악화된다. -> 학습을 다루기 위해 anomalies는 종종 normal 데이터와의 편차로 여겨진다. -> Anomaly Detection의 인기있는 접근 방식은 normal 훈련 예제만을 사용하여 dominant data representation을 배우는 one-class classifier를 훈련시키는 것이다.
but one-class classification (OCC)의 단점 1) 모든 normalcy variation을 capturing하지 않는다. (제한된 가용성) 2) OCC접근 방식은 여러 클래스와 동적 상황의 복잡한 문제에 적합하지 않다. => unseen normal activity는 anomalous한 결과를 초래할 수 있다.
Recently weakly supervised anomaly detection methods는 video level label을 이용하여 미세한 annotation을 얻는 비용을 줄이는데 상당히 많이 사용되었다. 일부 콘텐츠가 anomalous하고 모든 데이터가 normal 하면 전체 video는 anomalous하게 표시된다. <- 수동검사 필요 -> 상대적으로 비용 효율적이지만, 많은 실제 응용 프로그램에서는 비실용적이다.

annotation cost가 발생하지 않으면 anomaly detection training에 사용할 수 있는 수많은 video 영상이 있다. but 현재까지는 video anomaly detection을 위해 label이 지정되지 않은 train data를 활용하는 시도는 없다.
In this work, unsupervised mode for video anomaly detection <- weakly or one-class supervision보다 좀 더 잘 하기 위해 탐구한다.
- 이 문헌에서 ‘unsupervised’의 용어는 정상적인 train data를 가정하는 OCC 접근 방식을 의미한다.
video에서 unsupervised anomaly detection에 접근할 때, video가 정지 image에 비해 정보가 풍부하고 anomalous한 현상이 적게 일어난다는 사실을 이용하고, 구조화된 방식으로 그러한 도메인 지식을 활용하려고 시도한다.
이를 위해, Generative Cooperative Learning (GCL) 방식을 제안 = label이 지정되지 않은 video를 입력으로 받아들이고 frame 수준의 anomaly score를 출력으로 예측하는 방법을 배우는 생성 협동 학습 1) Generator와 Discriminator로 이루어져있다. 2) anomaly detection을 위해 상호 협력적(mutually cooperative)방식으로 훈련받는다.
Generator는 normal 반복을 reconstruction(재구성)할 뿐만 아니라 새로운 negative Learning을 사용하여 가능한 high-confidence anomalous representation을 왜곡한다. Discriminator는 instance가 anomaly일 확률을 추정한다.
Unsupervised anomaly detection을 위해 Generator에서 pseudo-label을 만들고 이를 사용하여 Discriminator를 훈련시킨다.
다음 단계에서 훈련된 Discriminator버전에서 pseudo-label을 만든다음 이를 사용하여 Generator를 개선한다.
Contributions label이 부착된 train data 없이 복잡한 시나리오에서 anomalous event을 찾아낼 수 있는 anomaly detection 방법을 제안한다. -> fully unsupervised mode의 video anomaly detection의 첫번째 시도이다.
사용하는 데이터 셋 = UCF-Crime, ShanghaiTech
[Method] 제안한 Generative Cooperative Learning (GCL)은 feature extractor, generator network, discriminator network, 두개의 pseudo-label generators로 구성된다.
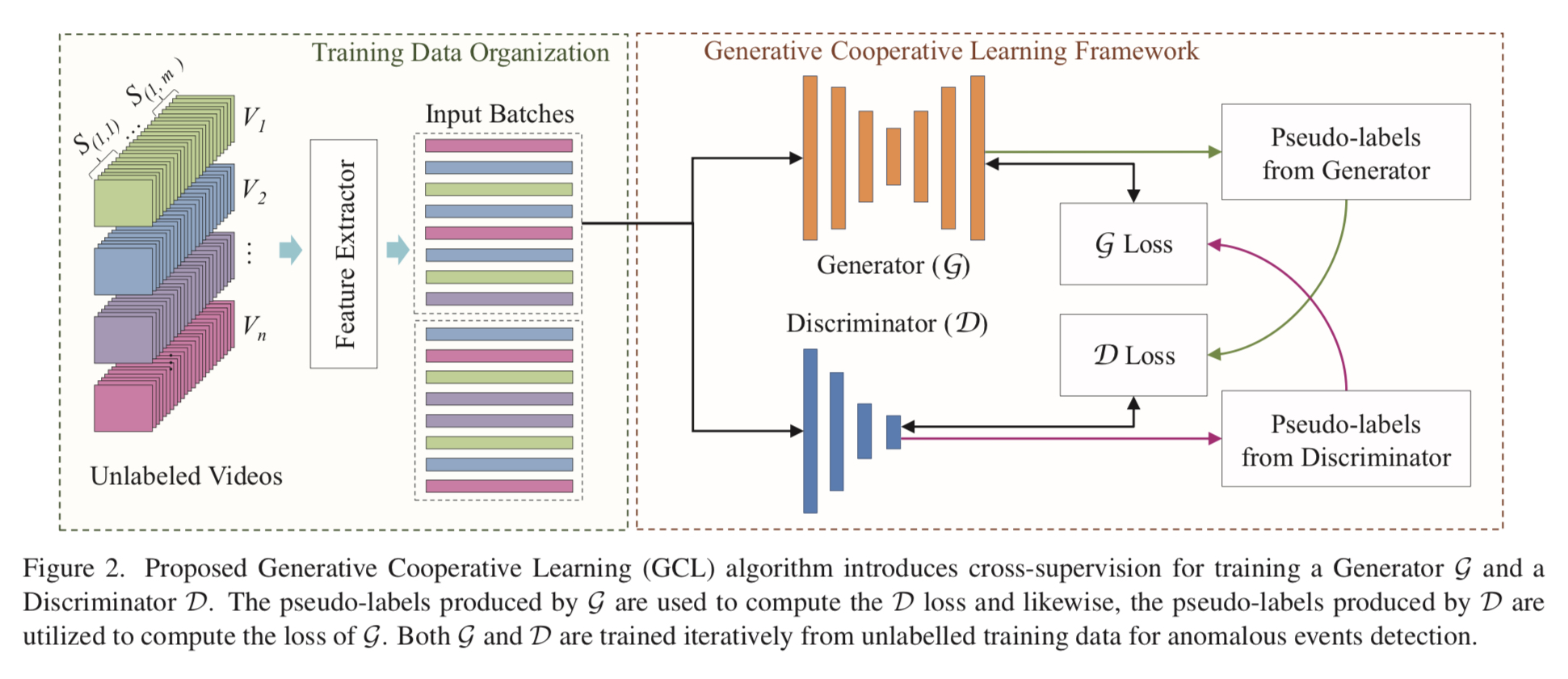
SOTA와 유사하게 계산 복잡성을 최소화하고 GCL의 훈련시간을 줄이기 위해 video를 deep feature extractor를 사용하여 compact features으로 변환. 모든 input video는 segment로 배열되며 features들은 randomly 하게 batch로 배열된다. 각 반복에서 무작위로 선택되는 batch는 GCL모델을 훈련시키는데 사용된다. -> 상세 내용은 Fig.2를 참조
n개의 비디오의 train dataset을 감안할 때, 모든 vidoe는 각각 p프레임의 겹치지 않는 segment S(i,j)로 분할되며, 여기에서 i는 [1,n]에 속하고 video 인덱스이다. j는 [i, m]에 속하며 segment index이다. segment 크기 p는 dataset의 모든 train 및 test video에서 동일하게 유지된다.
기존 wealky supervised anomaly detection에서 각 train 반복은 하나 이상의 완전한 비디오에서 수행된다. -> 최근 CLAWS Net은 일시적으로 일관된 feature의 여러 batch를 추출할 것을 제안했으며 각 feature는 network 작업에 무작위로 배치되었다. -> 기존 구성은 연속적인 배치간의 상관 관계를 최소화 하는데 도움이 된다. -> 배치 또는 비디오 수준에서 시간 순서를 유지하는 것이 중요하다. but -> 우리는 입력기능의 순서를 무작위화한다.
3.2 Generative Cooperative Learning
- anomaly detection을 위해 GCL은 AutoEncoder(AE)인 Generator G와 fully conneted classifier인 Discriminator D로 구성된다.
- 이 두 모델 모두 data annotation 없이 cooperative 방식으로 훈련되었다.
- one-class classification(OCC)처럼 normal class annotations을 사용하지 않으며, weakly supervised anomaly detection의 binary annotation도 사용하지 않는다.
AE를 사용하는 것은 모델이 전반적인 dominant data trend를 제한할 수 있다는 것이다. -> but discriminator로 사용되는 FC classification network는 supervised하고 noisy한 훈련을 할때 효율적으로 알려져있다. -> train을 하기 위해 G를 사용하여 생성된 첫번째 pseudo-annotation은 D를 훈련하는데 사용된다. -> D를 사용하여 생성된 pseudo-annotation은 G를 향상시키기 위해 사용된다. -> 따라서 두 모델은 각각 다른 모델이 만든 annotation을 alternate training 방식을 사용하여 훈련된다. -> 훈련 구성은 pseudo-labeling이 train 보다 개선되어 결과적으로 전반적인 anomaly detection 성능을 향상시키는 것을 목표로 한다.
3.2.1 Generator network G는 features을 입력으로 받아들이고 그 feature들을 출력으로 재구성(reconstruction)한다. 일반적으로 G는 reconstruction loss를 최소화한다. reconstruction loss
- b = batch size
- 샘플당 손실 평균
3.2.2 Pseudo Labels from Generator
- main idea : 높은 손실값을 anomaly하게 초래하는 feature vector와 normaly하게 작은 손실값을 초개하는 feature vector를 고려하는 것
3.2.3 Discriminator network Discriminator D는 binary classification network로 사용된다.
- batch b에 binary cross entropy loss를 최소화 하는 걸로 G로부터 나는 pseudo-annotation을 사용해서 train된다.
3.2.4 Pseudo Labels from Discriminator D의 output은 feature vector의 확률이다. (anomaly 할 확률) 더 높은 확률을 얻는 feature vector은 anomaly인것으로 간주한다. (threshold mechanism을 사용하여) D로 생성된 annotation은 G를 fine tune 한다. \[\tag{4}l_D^q = \begin{cases} 1, &\text{if } \hat P_{i,j}^q \ge L_D^{th} \\ 0, & otherwise , \end{cases}\]
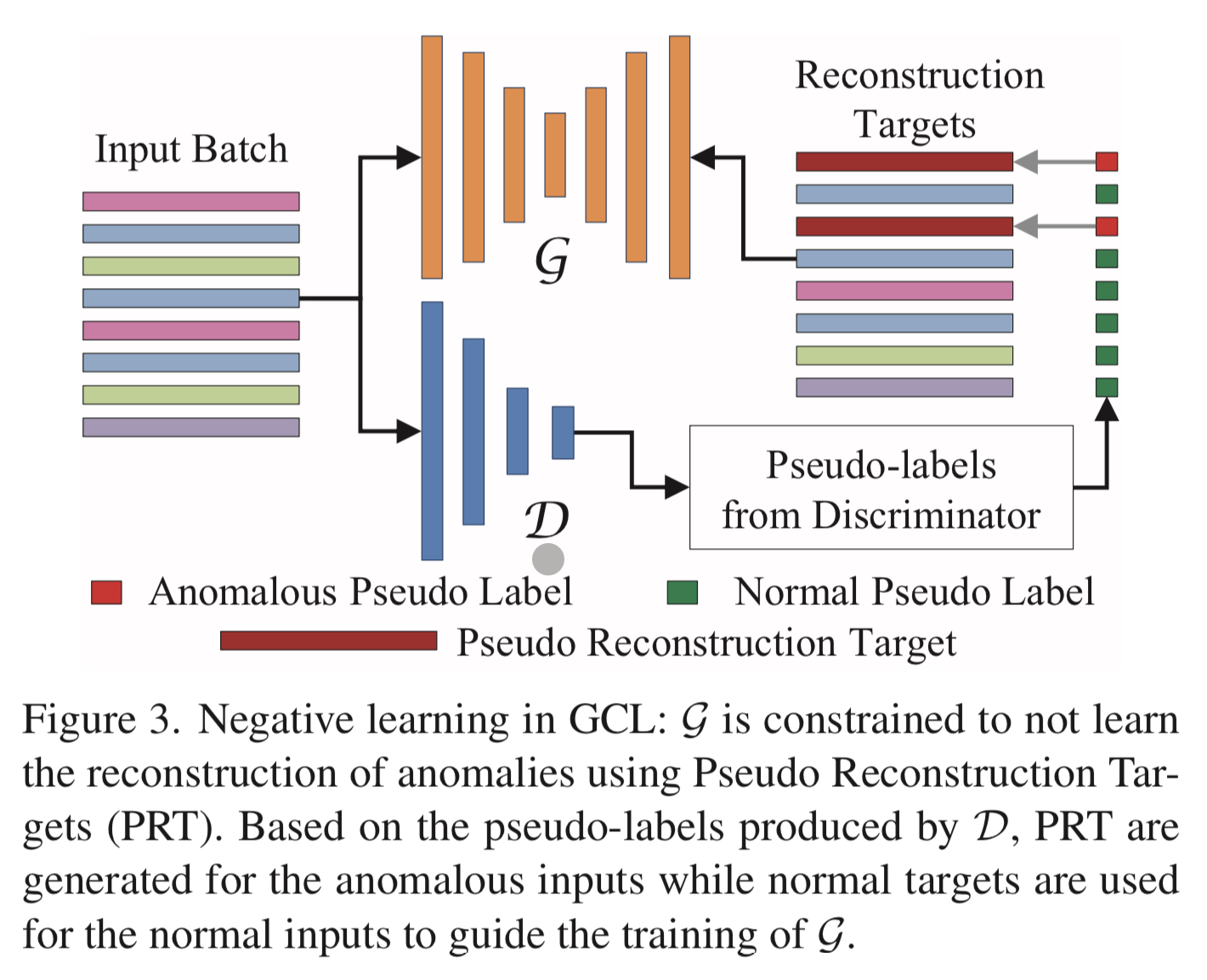 3.2.5 Negative Learning of Generator Network normaly <-> anomaly 간의 차별을 높이기 위해 G : anomaly pseudo-label이 있는 샘플을 제대로 재구성하지 못하도록 하고 noamly pseudo-label sample은 평소와 같이 최소한의 오류로 재구성한다.
3.2.5 Negative Learning of Generator Network normaly <-> anomaly 간의 차별을 높이기 위해 G : anomaly pseudo-label이 있는 샘플을 제대로 재구성하지 못하도록 하고 noamly pseudo-label sample은 평소와 같이 최소한의 오류로 재구성한다.
- negative learning : 데이터 포인트가 각 클래스에 속할 확률을 예측하는 것이 아니라 데이터 포인트가 각 클래스에 속하지 않을 확률을 예측한다. -> 확률이 가장 낮은 데이터 포인트를 올바른 클래스로 선택한다.
GCL에서 pseudo-label은 훈련이 진행됨에 따라 반복적으로 생성된다. -> 동일한 batch에서 anomaly and normaly 샘플이 모두 발생 가능하다. -> negative loss를 만드는 대신 abnormal sample을 제대로 재구성 하지 못하도록 강요한다. ( pseudo reconstruction target을 사용 )
pseudo target에 따라 4가지로 분류한다. 1) All ones Target : 원래 reconstruct target은 모든 1차원의 유사한 dimenstional vector로 대체한다. 2) Random Normal Target : 원래 reconstruction target은 임의로 선택된 normal label이 붙은 feature vector로 대체한다. 3) Random Gaussian noise Target : gaussian noise를 추가하여 교란한다. 4) No negative learning : normaly feature vector만 G의 train에 사용한다. \[\tag{5}L_G = {1 \over b}\sum_{q=1}^b\text{\textbardbl}t_{i,j}^q - {\widehat {f^q}_{i,j}}\text{\textbardbl}_2,\] \[\tag{6}t_{i,j}^q= \begin{cases} f_{i,j}^q, &\text{if } l_D^q=0 \\ 1\in \R^d, & l_D^q=1 , \end{cases}\]
3.3 Self-Supervised Pre-training
- constaint의 부록은 수렴에 영향을 미칠 수 있으며 local minima 에 갖힐 수 있다.
- Auto Encoder는 지배적인 representation을 포착한다.
- anomal은 희박하고 normal feature은 풍부함에도 불구하고 모든 training data를 G에 pre-train 시켜야 했다.
Using the fact 1) video의 사건은 sequence하게 일어난다. 2) anomalous한 frame은 normal보다 더 eventful 하다. 3) consecutive feature vector들간의 차이를 G에게 pre-train시킨다.
- feature vector는 pre-training 만을 위해 사용된다.
- 그러나 이방법은 anomalous한 사건의 완벽한 제거를 보장하지 않는다. : 훈련을 시작하기 위해 G의 효과적인 초기화를 위해 data를 정리한다.
- G가 pre-trained되면 D를 pre-train하는데 사용되는 pseudo-label을 생성한다.
- 이 단계에서 G에 의해 생성된 pseudo-label은 꽤 noisy해서 G는 형편없다. D의 역할은 noisy한 label에서도 anomal/normal을 잘 구분하기 때문에 D는 좋다.
- G와 D는 서로 학습한다.
3.4 Anomaly Scoring
- test time에 final anomaly score를 계산하기 위해 D의 prediction score or G의 reconstruction error를 사용하는데 G는 형편없고 D는 효율적인 측면을 보이기 때문에 이 연구에서는 D의 prediction score를 사용해 계산한다.
- Experiments
- Datasets 1) UCR-Crime(UCFC) - 128시간에 걸친 CCTV 감시 카메라에 의해 덮인 13가지 범주의 실제 anomalous event가 포함되어있다. - Unsupervised 환경에서 training-split label을 사용하지 않고 unlabel된 training video를 사용한다. 2) ShanghaiTech - 437개의 video에 걸쳐 13개의 다른 위치에 있는 대학 캠퍼스에서 진행된 anomalous event가 포함되어있다. - 원래 교육을 위해 제공된 normal video와 함께 OCC를 위해 제안되었지만 Zhong et al.이 weakly-supervised algorithm을 학습하기 위해 재구성했다. - training-split label을 사용하지 않고 unlabel된 training video를 사용한다.
- Evaluation Measures
- 기존 방법에 따라 평가와 비교를 위해 area under ROC curve를 사용한다.
- AUC는 두 dataset에서 모두 test video의 frame-level annotation 기반으로 계산된다.
4.1 Comoparisons with State-Of-The-Art (SOTA)
- 제안된 GCL 방식은 어떤 종류의 annotation도 사용하지 않고 unsupervised 방법으로 사용된다.
- no pre-training : $GCL_B$
- pre-training : $GCL_{PT}$
- combined with OCC (pre-trained autoencoder) : $GCL_{OCC}$
- combined with weakly-supervised (pre-trained) : $GCL_{WS}$